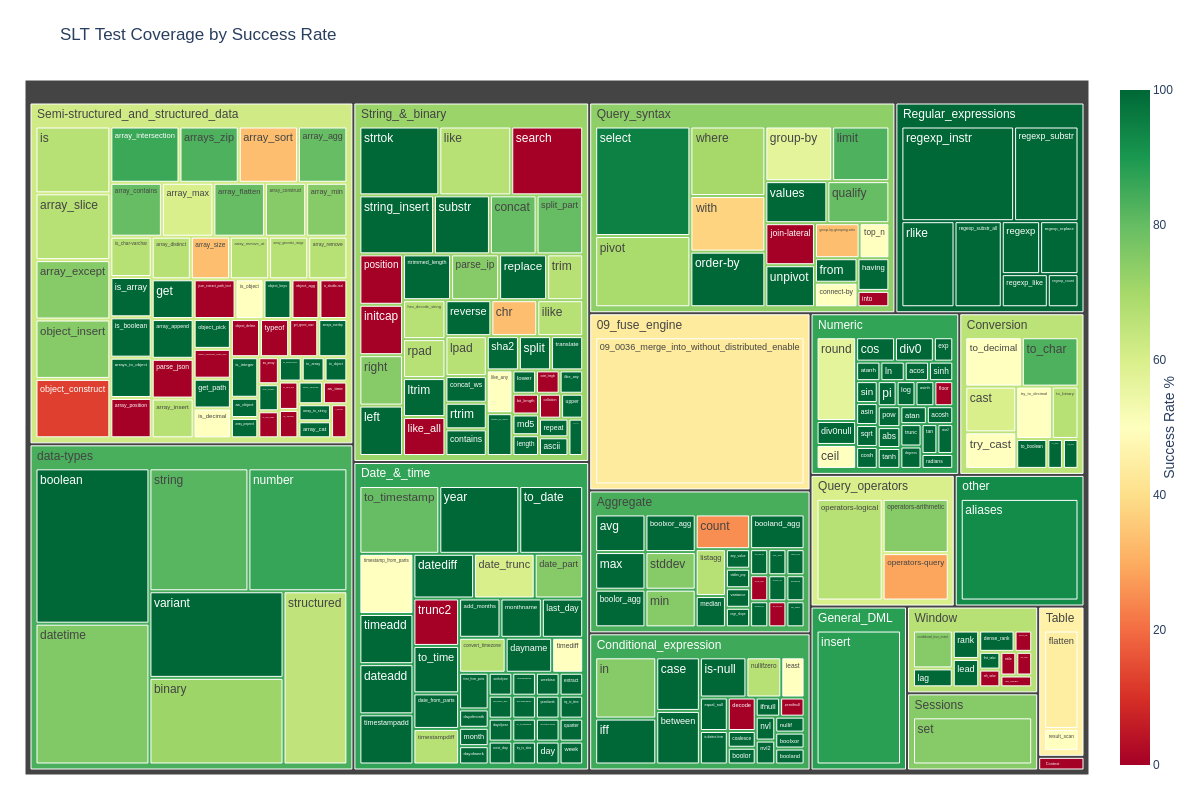
Running TPC-H 1000 on Apache DataFusion on a single node
Andrey Oleksiuk

Running TPC-H 1000 on Apache DataFusion on a single node
TL;DR: We successfully executed the full TPC‑H benchmark at scale factor 1000 (≈1 TB) using Apache DataFusion on a single node. To our knowledge, this is the first public demonstration of all 22 queries completing at this scale. This benchmark aligns with our belief that a single well‑provisioned machine is sufficient for the vast majority of data workloads.
Why we ran TPC‑H 1000 on a single node
At Embucket, our philosophy is simple: the majority of production data workloads don’t require a distributed fleet of machines. Modern cloud instances offer staggering compute and memory capacity, and most real‑world datasets are smaller than 1 TB. Testing TPC‑H at scale factor 1000 (SF1000) is a way to validate that belief and to push the limits of modern query engines in a controlled environment.
We chose Apache DataFusion for this test because it’s a fast‑evolving, Rust‑native query engine that we’re using as a building block for our broader mission: building Autonomous Data Infrastructure.
Benchmark environment
Hardware
- AWS EC2
r6gd.metal(64 vCPUs, 512 GB RAM, NVMe SSD) - Region:
us-east-2
Data format & storage
- TPC‑H data generated via
tpchgen-cli(Rust) - Stored as 20 Parquet files per table
- Benchmarks run with both local SSD and remote S3 storage (local SSD used for final measurements)
Execution method
datafusion-cliwithdatafusion.execution.target_partitions = 32- Queries executed one at a time
- Each query run twice:
- First run: cold cache
- Second run: hot cache (timings averaged across hot runs)
Metrics captured
- Per‑query runtimes
- Total runtime
- Memory and CPU usage monitored externally (no exhaustive logs)
- Profiling via
EXPLAIN ANALYZE
The problematic queries: Q18 and Q21
Out of the 22 TPC‑H queries, two presented significant challenges at SF1000: Q18 and Q21. Initial attempts to run the original versions resulted in out‑of‑memory errors or excessive runtimes. We tried to fix this by tuning:
- Adjusting the number of partitions (higher parallelism = higher memory pressure)
- Enabling spilling to disk with a fast local SSD
Despite these, we faced instability: tuning for one query often broke the other. Ultimately, we rewrote both queries with structural optimizations.
How we rewrote the queries
Q18: The original query made two passes over the massive lineitem table. Intermediate results were huge due to the orders × lineitem join. We rewrote the query to filter lineitem early, reduce passes, and streamline joins.
Q21: The original used three self‑joins and EXISTS/NOT EXISTS subqueries on lineitem. We transformed these into semi/anti‑joins over pre‑filtered subsets. This drastically reduced row movement, enabled cheaper join strategies, and improved query plan stability.
Query rewrites
Original Q18
SELECT c_name, c_custkey, o_orderkey, o_orderdate, o_totalprice, SUM(l_quantity)
FROM customer, orders, lineitem
WHERE o_orderkey IN (
SELECT l_orderkey
FROM lineitem
GROUP BY l_orderkey
HAVING SUM(l_quantity) > 313
)
AND c_custkey = o_custkey
AND o_orderkey = l_orderkey
GROUP BY c_name, c_custkey, o_orderkey, o_orderdate, o_totalprice
ORDER BY o_totalprice DESC, o_orderdate
LIMIT 100;Modified Q18
WITH order_totals AS (
SELECT l_orderkey, SUM(l_quantity) AS sum_qty
FROM lineitem
GROUP BY l_orderkey
HAVING SUM(l_quantity) > 300
)
SELECT c.c_name, c.c_custkey, o.o_orderkey, o.o_orderdate, o.o_totalprice, ot.sum_qty
FROM order_totals ot
JOIN orders o ON o.o_orderkey = ot.l_orderkey
JOIN customer c ON c.c_custkey = o.o_custkey
ORDER BY o.o_totalprice DESC, o.o_orderdate
LIMIT 100;Original Q21
SELECT s_name, COUNT(*) AS numwait
FROM supplier, lineitem l1, orders, nation
WHERE s_suppkey = l1.l_suppkey
AND o_orderkey = l1.l_orderkey
AND o_orderstatus = 'F'
AND l1.l_receiptdate > l1.l_commitdate
AND EXISTS (
SELECT * FROM lineitem l2
WHERE l2.l_orderkey = l1.l_orderkey AND l2.l_suppkey <> l1.l_suppkey
)
AND NOT EXISTS (
SELECT * FROM lineitem l3
WHERE l3.l_orderkey = l1.l_orderkey
AND l3.l_suppkey <> l1.l_suppkey
AND l3.l_receiptdate > l3.l_commitdate
)
AND s_nationkey = n_nationkey
AND n_name = 'ARGENTINA'
GROUP BY s_name
ORDER BY numwait DESC, s_name
LIMIT 100;Modified Q21
WITH failed_orders AS (
SELECT o_orderkey FROM orders WHERE o_orderstatus = 'F'
),
order_supplier_counts AS (
SELECT l.l_orderkey, COUNT(DISTINCT l.l_suppkey) AS num_suppliers
FROM lineitem l
INNER JOIN failed_orders fo ON l.l_orderkey = fo.o_orderkey
GROUP BY l.l_orderkey
HAVING COUNT(DISTINCT l.l_suppkey) > 1
),
late_receipts AS (
SELECT l.l_orderkey, l.l_suppkey
FROM lineitem l
INNER JOIN failed_orders fo ON l.l_orderkey = fo.o_orderkey
WHERE l.l_receiptdate > l.l_commitdate
),
saudi_late_receipts AS (
SELECT lr.l_orderkey, lr.l_suppkey, s.s_name
FROM late_receipts lr
INNER JOIN supplier s ON lr.l_suppkey = s.s_suppkey
INNER JOIN nation n ON s.s_nationkey = n.n_nationkey
WHERE n.n_name = 'SAUDI ARABIA'
)
SELECT slr.s_name AS s_name, COUNT(*) AS numwait
FROM saudi_late_receipts slr
INNER JOIN order_supplier_counts osc ON slr.l_orderkey = osc.l_orderkey
WHERE NOT EXISTS (
SELECT 1 FROM late_receipts lr2
WHERE lr2.l_orderkey = slr.l_orderkey AND lr2.l_suppkey <> slr.l_suppkey
)
GROUP BY slr.s_name
ORDER BY numwait DESC, s_name
LIMIT 100;Results

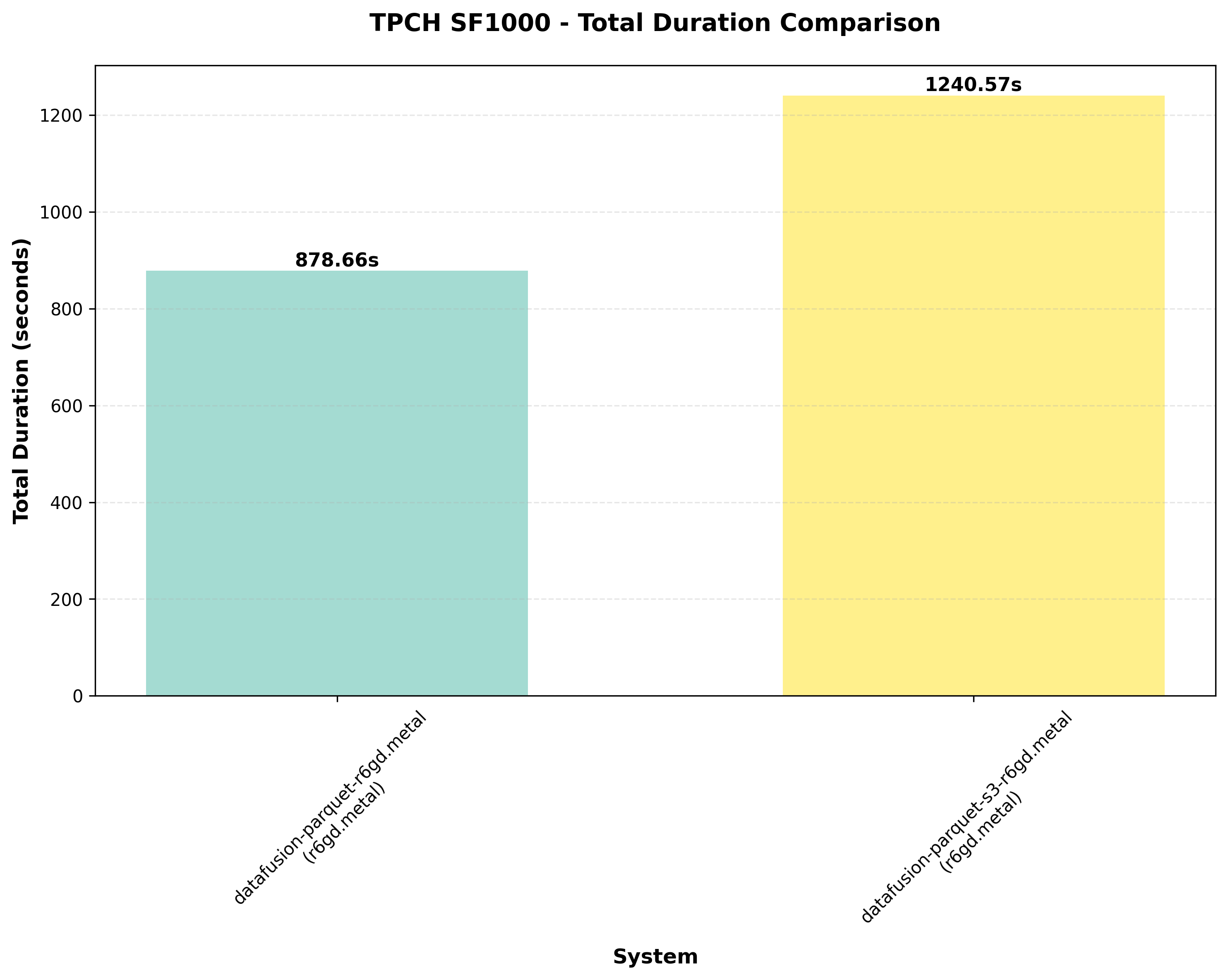
All the measurements with the code to reproduce this benchmark can be found here: https://github.com/Embucket/benchmarks/tree/main/datafusion
Closing thoughts
We believe this benchmark is an important milestone for the DataFusion community. It shows that with the right setup and some careful query engineering, DataFusion can run TPC‑H 1000 on a single node.
This is only the beginning. As part of our journey toward Autonomous Data Infra, we’ll continue pushing the boundaries of what can be done with modern data engines on modern hardware.
Stay tuned.